Road map to become a data scientist
Becoming a data scientist involves a combination of
education, technical skills, and practical experience. Here's a road map to
help you navigate the path towards becoming a data scientist:
1) Education: Obtain a solid educational foundation. A bachelor's or master's degree in a field such as computer science, mathematics, statistics, or a related quantitative discipline is typically beneficial. Courses in data analysis, machine learning, statistics, and programming are highly recommended.

To pursue a career in data science, it is beneficial to have a strong educational background. Here are the steps you can take to gain education in the field of data science:
v Earn a bachelor's degree: Begin by obtaining a
bachelor's degree in a relevant field such as mathematics, statistics, computer
science, or engineering. These fields provide a solid foundation in
mathematical and computational skills necessary for data science.
v Master's degree in data science or related
field: While a bachelor's degree can get you started, a master's degree in data
science or a related field can significantly enhance your knowledge and make
you more competitive in the job market. Look for programs that focus on data
analysis, machine learning, statistics, and programming.
v Online courses and certifications: Many online
platforms offer data science courses and certifications that can help you
acquire specific skills and knowledge in the field. Websites like Coursera,
edX, and Udemy offer a wide range of courses on topics such as data analysis,
machine learning, and programming languages like Python or R.
v Participate in data science competitions:
Engaging in data science competitions, such as Kaggle, can provide practical
experience and help you build a strong portfolio of projects. These
competitions allow you to work on real-world datasets and solve complex
problems, which can be valuable for showcasing your skills to potential
employers.
v Attend workshops and conferences: Attend
industry conferences, workshops, and seminars focused on data science. These
events provide opportunities to network with professionals, learn about the
latest advancements, and gain insights into industry trends.
v Gain practical experience: Apply your
knowledge by working on data-related projects. Look for internships, research
opportunities, or freelance work that involves data analysis, machine learning,
or statistical modeling. Practical experience is crucial in demonstrating your
ability to apply theoretical knowledge to real-world scenarios.
v Continuously learn and stay updated: Data
science is a rapidly evolving field, so it's essential to stay updated with the
latest technologies and techniques. Follow influential data science blogs, read
research papers, and explore online resources to stay abreast of new
developments in the field.
Remember that while education is
valuable, practical experience and a strong portfolio of projects are equally
important in the data science field. By combining education, hands-on
experience, and continuous learning, you can establish a solid foundation and
excel as a data scientist.
2) Mathematics and Statistics: Develop a strong understanding of mathematics and statistics concepts. Focus on areas such as linear algebra, calculus, probability, and statistical inference. These mathematical foundations are crucial for understanding and implementing data science algorithms and models.

v Mathematics and statistics play a fundamental
role in the field of data science. Here are some key areas within mathematics
and statistics that are particularly relevant for data scientists:
v Linear Algebra: Linear algebra is used
extensively in data science for tasks such as matrix operations, linear
regression, dimensionality reduction, and eigenvalue decomposition.
Understanding concepts like vectors, matrices, vector spaces, and eigenvectors
is essential.
v Calculus: Calculus provides the foundation for
optimization algorithms used in machine learning, such as gradient descent.
Familiarity with concepts like differentiation, integration, optimization, and
partial derivatives is important.
v Probability Theory: Probability theory is
essential for understanding uncertainty and making probabilistic predictions.
Concepts such as random variables, probability distributions, conditional
probability, and Bayes' theorem are frequently used in areas like statistical
modeling, hypothesis testing, and Bayesian inference.
v Statistics: Statistics enables data scientists
to analyze and interpret data. Knowledge of statistical techniques, such as
hypothesis testing, confidence intervals, regression analysis, and experimental
design, is crucial for drawing meaningful insights from data.
v Multivariate Calculus: Multivariate calculus
extends calculus to multiple dimensions and is relevant for optimization
problems in machine learning and deep learning. Understanding partial derivatives,
gradients, and the chain rule is important when working with functions of
multiple variables.
v Probability Distributions: Familiarity with
common probability distributions, such as the normal distribution, binomial
distribution, and Poisson distribution, is important for modeling and analyzing
data. Understanding their properties and parameters aids in statistical
inference and modeling.
v Statistical Learning Theory: Statistical
learning theory provides the theoretical foundation for machine learning algorithms.
Concepts like bias-variance tradeoff, overfitting, regularization, and model
evaluation metrics help data scientists develop effective and robust models.
It's important to have a solid
understanding of these mathematical and statistical concepts to perform data
analysis, develop models, and make informed decisions in data science. Building
a strong foundation in mathematics and statistics will empower you to apply
advanced techniques and algorithms effectively in your data science work.
3)
Programming Skills:
Learn programming languages commonly used in data science, such as Python or R.
These languages have extensive libraries and frameworks for data manipulation,
analysis, and machine learning. Familiarize yourself with data processing
libraries like NumPy and pandas, as well as machine learning libraries like
scikit-learn and TensorFlow.

Programming skills are essential for
data scientists as they enable them to manipulate, analyze, and derive insights
from data. Here are some programming skills that are particularly important for
data scientists:
v Python: Python is one of the most widely used
programming languages in data science due to its simplicity, versatility, and
extensive ecosystem of libraries and frameworks. It provides powerful tools for
data manipulation, analysis, and machine learning, such as NumPy, pandas,
scikit-learn, and TensorFlow/PyTorch for deep learning.
v R: R is another popular programming language
for data science, especially in statistical analysis and visualization. It
offers a vast collection of packages like dplyr, ggplot2, and caret that
facilitate data manipulation, statistical modeling, and exploratory data
analysis.
v SQL: SQL (Structured Query Language) is
crucial for working with relational databases, which often store large volumes
of structured data. Proficiency in SQL allows data scientists to extract,
transform, and analyze data efficiently using database management systems like
MySQL, PostgreSQL, or SQLite.
v Data Manipulation: Data scientists should be
skilled in data manipulation techniques such as cleaning, filtering, merging,
and reshaping datasets. Libraries like pandas in Python and dplyr in R provide
powerful functions and methods to handle various data manipulation tasks
effectively.
v Data Visualization: Being able to effectively
communicate insights through visualizations is vital. Python libraries like
Matplotlib, Seaborn, and Plotly, as well as R libraries like ggplot2 and shiny,
enable data scientists to create informative and visually appealing plots,
charts, and interactive dashboards.
v Version Control: Proficiency in version
control systems like Git is important for collaborative work, tracking changes,
and maintaining code repositories. Git allows data scientists to manage
codebase, collaborate with others, and easily revert to previous versions if
needed.
v Big Data Technologies: Familiarity with big
data technologies like Apache Hadoop, Apache Spark, and distributed computing
frameworks such as Apache Hive or Apache Pig is valuable. These tools enable
processing and analysis of large-scale datasets that don't fit into the memory
of a single machine.
v Web Scraping: Web scraping is the process of
extracting data from websites, and it can be valuable for acquiring data for
analysis. Python libraries like BeautifulSoup and Scrapy provide convenient
tools for web scraping tasks.
v Containerization: Knowledge of
containerization platforms like Docker and container orchestration systems like
Kubernetes is becoming increasingly important. Containerization allows data
scientists to package their code, dependencies, and environments, ensuring
reproducibility and portability.
v Machine Learning Frameworks: Understanding and
working with popular machine learning frameworks like scikit-learn, TensorFlow,
and PyTorch is essential for building and deploying machine learning models.
These frameworks provide a range of algorithms and tools for tasks like classification,
regression, clustering, and deep learning.
Continuous learning and exploration of
new tools and libraries is crucial in the ever-evolving field of data science.
By honing these programming skills, data scientists can efficiently extract
insights from data and develop robust solutions to complex problems.
4)
Data Manipulation and Analysis:
Gain proficiency in data manipulation and analysis techniques. Learn how to
clean and preprocess data, handle missing values, and perform exploratory data
analysis. Practice using tools like SQL for querying databases and tools like
Excel or Google Sheets for data analysis and visualization.

Data
manipulation and analysis are fundamental tasks for data scientists. These
tasks involve preparing, cleaning, transforming, and analyzing data to extract
insights, build models, and make data-driven decisions. Here's an overview of
the data manipulation and analysis process for data scientists:
v Data Collection:
Data scientists gather data from diverse sources, such as databases, APIs, data
warehouses, or external datasets. They ensure the data is relevant to the
problem at hand and understand its structure, quality, and limitations.
v Data Cleaning and
Preprocessing: Data cleaning involves addressing issues like missing values,
outliers, inconsistencies, and noise. Data scientists employ techniques such as
imputation, filtering, normalization, and feature scaling to ensure the data is
clean, consistent, and suitable for analysis.
v Data Transformation
and Feature Engineering: Data scientists transform the data by creating new
features, combining existing ones, or applying mathematical operations to
enrich its representation. Feature engineering involves extracting meaningful
insights from the data and creating input variables that enhance model
performance.
v Exploratory Data
Analysis (EDA): EDA helps data scientists understand the data, identify
patterns, correlations, and outliers, and generate hypotheses. They visualize
the data using plots, graphs, and statistical summaries to gain insights and
guide subsequent analysis.
v Statistical
Analysis and Hypothesis Testing: Data scientists apply statistical techniques
and hypothesis testing to validate assumptions, assess significance, and draw
conclusions. They use statistical methods such as regression analysis, ANOVA,
t-tests, or chi-square tests to uncover relationships and patterns in the data.
v Machine Learning Modeling:
Data scientists employ machine learning algorithms to build models that can
make predictions, classifications, or clusterings. They select appropriate
algorithms, split the data into training and testing sets, train the models,
tune hyperparameters, and evaluate their performance.
v Model Evaluation
and Optimization: Data scientists assess the performance of their models using
evaluation metrics like accuracy, precision, recall, or mean squared error.
They iterate on the models, fine-tuning hyperparameters, optimizing feature
selection, or applying regularization techniques to improve performance.
v Data Visualization
and Reporting: Data scientists use visualizations, charts, and interactive
dashboards to communicate their findings effectively. They present insights,
model performance, and recommendations to stakeholders in a clear and
interpretable manner.
v Deployment and
Monitoring: Data scientists deploy their models into production environments to
make them accessible for real-time predictions. They monitor the performance of
the deployed models, analyze feedback, and continuously update and refine them based
on new data or changing business requirements.
Data
scientists employ programming languages like Python or R, along with libraries
such as pandas, NumPy, scikit-learn, TensorFlow, or PyTorch, to manipulate and
analyze data effectively.
Data
manipulation and analysis require a combination of technical expertise, domain
knowledge, critical thinking, and creativity. Data scientists leverage these
skills to extract valuable insights, build accurate models, and drive
data-driven decision-making in various fields and industries.
5)
Machine Learning:
Develop a strong understanding of machine learning algorithms and techniques.
Study supervised learning (classification, regression), unsupervised learning
(clustering, dimensionality reduction), and other topics like ensemble methods
and deep learning. Implement algorithms from scratch and work with popular
machine learning libraries to build and evaluate models.

Machine
learning is a powerful tool that data analysts can leverage to gain insights,
make predictions, and automate decision-making processes. While data scientists
often specialize in building and fine-tuning machine learning models, data
analysts can still utilize machine learning techniques to enhance their data
analysis capabilities. Here's how data analysts can leverage machine learning:
v Supervised
Learning: Data analysts can apply supervised learning algorithms to build
predictive models based on labeled data. They can use algorithms like linear
regression, logistic regression, decision trees, random forests, or support
vector machines to make predictions or classify data. This allows analysts to
forecast outcomes, identify patterns, or segment data based on specific
criteria.
v Unsupervised
Learning: Unsupervised learning techniques can help data analysts discover
hidden patterns or groupings in data. Algorithms like clustering (k-means,
hierarchical clustering), dimensionality reduction (principal component
analysis, t-SNE), or association rule mining (Apriori) can assist in
identifying meaningful structures and relationships within datasets.
v Natural Language
Processing (NLP): NLP techniques enable data analysts to extract insights from
text data. They can utilize techniques like text classification, sentiment
analysis, topic modeling (Latent Dirichlet Allocation), or named entity
recognition to process and analyze text data from sources like customer
reviews, social media, or survey responses.
v Time Series
Analysis: Time series analysis techniques help analysts analyze and forecast
data points over time. Methods like ARIMA (autoregressive integrated moving
average), exponential smoothing, or LSTM (long short-term memory) neural
networks can be employed to model and predict trends, seasonality, or future
values in time series data.
v Feature
Engineering: Data analysts can apply feature engineering techniques to derive
meaningful variables from raw data, enhancing the performance of machine
learning models. This involves transforming, combining, or creating new
features based on domain knowledge or data insights to better represent the
underlying patterns or relationships.
v Model Evaluation
and Interpretation: Data analysts can assess the performance of machine
learning models using appropriate evaluation metrics, such as accuracy,
precision, recall, or mean squared error. They can interpret the model's
results, understand the feature importance, or conduct sensitivity analysis to
gain insights into the model's behavior.
v Automation and
Decision Support: By applying machine learning techniques, data analysts can
automate repetitive tasks, classify or categorize data automatically, and
develop decision support systems. This allows analysts to streamline processes,
extract insights more efficiently, and provide actionable recommendations to
stakeholders.
While data
analysts may not be responsible for the full end-to-end model development
process like data scientists, having a working knowledge of machine learning
techniques can significantly enhance their ability to analyze data, derive
insights, and deliver impactful results. It's important for data analysts to
understand the strengths, limitations, and appropriate use cases of different
machine learning algorithms to make informed decisions and maximize the value
of their analyses.
6)
Data Visualization: Learn
how to effectively communicate insights through data visualization. Become
familiar with libraries like Matplotlib, Seaborn, or ggplot in R for creating
visual representations of data. Understand principles of data visualization and
design to create clear and impactful visualizations.

Data
visualization is a critical aspect of data analysis for data analysts. It
involves creating visual representations of data to effectively communicate
insights, patterns, and trends. Here are some key considerations and techniques
for data visualization as a data analyst:
v Selecting the Right
Chart Types: Choose appropriate chart types based on the data and the message
you want to convey. Common types include bar charts, line charts, scatter
plots, histograms, pie charts, and heatmaps. Each chart type has its strengths
and is suited for different types of data and analysis goals.
v Simplify and Focus:
Keep visualizations simple and focused on the key message or insights. Avoid
cluttering the visuals with unnecessary elements that might distract viewers.
Emphasize the most important aspects of the data and highlight the main
findings.
v Use Clear Labels
and Titles: Ensure that your visualizations have clear labels for axes,
legends, and data points. Use concise and informative titles that accurately
describe the content of the visualization. Well-labeled visuals make it easier
for viewers to interpret and understand the information being presented.
v Utilize Color
Effectively: Choose colors thoughtfully to enhance the readability and
aesthetics of your visualizations. Use color to highlight important elements or
distinguish different categories. However, be cautious about using too many
colors or color combinations that may confuse viewers or misrepresent the data.
v Incorporate
Interactive Elements: Interactive visualizations can provide an engaging
experience for viewers and enable them to explore the data further. Use
interactive features such as tooltips, zooming, filtering, or sorting to allow
users to interact with the visualization and uncover additional insights.
v Tell a Story: Arrange
your visualizations in a logical order that tells a coherent story. Use a
combination of visuals, textual annotations, and supporting context to guide
viewers through the data analysis process. The narrative flow helps viewers
understand the data's context and the key insights derived from it.
v Data Drill-Down:
Provide opportunities for users to drill down into the data behind the
visualizations. This allows viewers to access more detailed information or
explore specific subsets of the data. Interactive drill-down features empower
users to derive deeper insights and make more informed decisions.
v Choose the Right
Tools: Data analysts can utilize a range of tools and software for data
visualization, such as Tableau, Power BI, Excel, Python libraries like matplotlib
and seaborn, or R packages like ggplot2. Familiarize yourself with the
capabilities and features of different tools to choose the one that best suits
your needs and skillset.
Remember,
data visualization is a powerful way to communicate complex information
effectively. As a data analyst, focus on creating visually appealing,
informative, and user-friendly visualizations that support data-driven
decision-making and facilitate understanding for your intended audience.
7)
Big Data and Distributed Computing:
Gain knowledge of working with big datasets and distributed computing
frameworks such as Apache Hadoop or Apache Spark. Understand concepts like
parallel processing, distributed file systems, and data processing pipelines.

Big data
and distributed computing are crucial concepts for data scientists dealing with
large-scale datasets that cannot be processed on a single machine. Here's an
overview of big data and distributed computing in the context of data science:
v Big Data: Big data
refers to datasets that are large, complex, and beyond the capacity of
traditional data processing tools. Big data is characterized by the volume
(large amount of data), velocity (high data generation and processing speed),
and variety (data in different formats and from diverse sources).
v Distributed
Computing: Distributed computing involves breaking down computational tasks
into smaller subtasks and distributing them across multiple machines or nodes
in a network. This approach allows for parallel processing and enables
efficient handling of big data by harnessing the collective computational power
of multiple machines.
v Hadoop: Apache
Hadoop is a widely used open-source framework for distributed computing. It
provides a scalable and fault-tolerant infrastructure for processing and
analyzing big data across clusters of commodity hardware. Hadoop consists of
Hadoop Distributed File System (HDFS) for distributed storage and MapReduce for
distributed data processing.
v Spark: Apache Spark
is another popular open-source framework for distributed computing that excels
in processing big data with speed and efficiency. Spark provides an in-memory
computing engine that enables fast and iterative data processing, making it
well-suited for machine learning tasks, streaming data, and interactive data
analysis.
v Data Parallelism:
Distributed computing frameworks leverage data parallelism, where large
datasets are divided into smaller partitions, and each partition is processed
independently by different nodes in parallel. This approach allows for
efficient and scalable processing of big data across multiple machines.
v Cluster Computing:
Distributed computing typically relies on clusters, which are groups of
interconnected machines working together. Each machine in the cluster can
process a subset of the data, and the results are combined to generate the
final output. Clusters can be set up on-premises or on cloud platforms like
Amazon Web Services (AWS) or Google Cloud Platform (GCP).
v Scalability and
Fault Tolerance: Distributed computing frameworks provide scalability, allowing
the system to handle growing datasets and increased computational demands by
adding more machines to the cluster. They also offer fault tolerance mechanisms
to ensure that processing continues even if individual machines fail.
v Data Partitioning
and Shuffling: When processing big data, distributed computing frameworks
handle data partitioning, where data is split into chunks and distributed
across machines. They also manage data shuffling, which involves redistributing
data across machines based on the requirements of the computational tasks.
Data
scientists working with big data can leverage distributed computing frameworks
like Hadoop and Spark to efficiently process, analyze, and derive insights from
large datasets. By harnessing the power of distributed computing, data
scientists can tackle complex data challenges, perform advanced analytics, and
build scalable machine learning models that operate on big data.
8)
Domain Knowledge:
Acquire domain-specific knowledge relevant to the industry you are interested
in. Data science is often applied in various domains like healthcare, finance,
marketing, or engineering. Understanding the specific challenges and nuances of
a particular industry will make you more effective as a data scientist.

Domain knowledge refers to expertise and understanding of a specific industry,
field, or subject matter. It plays a crucial role in the work of data
scientists as it enables them to effectively analyze data within the context of
the domain they are working in. Here's why domain knowledge is important for
data scientists:
v Contextual
Understanding: Domain knowledge allows data scientists to interpret and
understand data in the context of the specific industry or field they are
working in. It helps them identify relevant variables, understand
relationships, and make informed decisions based on the unique characteristics
of the domain.
v Data Understanding
and Quality Assessment: With domain knowledge, data scientists can assess the
quality and relevance of data. They can identify potential biases,
inconsistencies, or missing data that may impact the analysis. Understanding
the data sources and collection processes helps ensure that the data is fit for
purpose and aligned with the specific domain requirements.
v Feature Engineering
and Selection: Domain knowledge aids in feature engineering, where data
scientists create new features based on their understanding of the domain. They
can select or engineer variables that are most relevant for the specific
problem at hand, incorporating their expertise to capture domain-specific
insights and patterns.
v Model
Interpretation: In complex domains, understanding the domain is critical for
interpreting and validating the results of machine learning models. Data
scientists with domain knowledge can explain the implications and limitations
of the models in terms that domain experts can understand, facilitating
effective collaboration and decision-making.
v Problem Framing and
Goal Definition: Domain knowledge enables data scientists to frame business
problems and define goals in a way that aligns with the objectives and
challenges of the specific domain. It helps in identifying relevant data-driven
opportunities, designing appropriate experiments, and formulating actionable
insights.
v Identifying
Relevant Questions: Domain expertise allows data scientists to ask relevant
questions and identify specific problems or challenges that can be addressed
using data analysis. It helps them focus on high-impact areas and develop
data-driven solutions that provide value within the domain.
v Effective
Communication: Data scientists with domain knowledge can effectively
communicate their findings, insights, and recommendations to domain experts,
stakeholders, or decision-makers. They can bridge the gap between technical
analysis and domain-specific requirements, ensuring that the results are
actionable and understood within the domain context.
While
domain knowledge is valuable, data scientists should also collaborate with
domain experts to gain deeper insights and validate their findings. Building
domain expertise takes time and involves continuous learning and immersion in
the specific industry or field. By combining technical skills with domain
knowledge, data scientists can provide valuable insights, solve complex
problems, and drive meaningful impact within their respective domains.
9)
Projects and Portfolio:
Build a strong portfolio of data science projects. Work on real-world datasets
or participate in data science competitions to demonstrate your skills.
Showcase your ability to tackle data-related problems, apply machine learning
techniques, and communicate insights effectively.
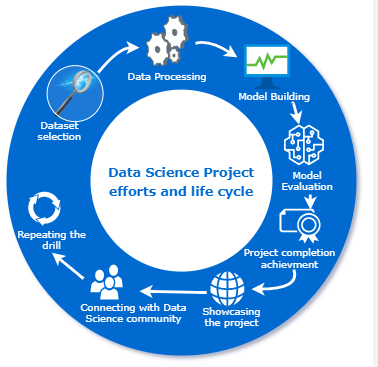
v Kaggle
Competitions: Participate in Kaggle competitions to showcase your skills and
problem-solving abilities. Kaggle provides a platform where you can work on
real-world datasets and compete with other data scientists. Choose competitions
that align with your interests and tackle a range of problem domains to
demonstrate versatility.
v Personal Projects:
Undertake personal projects that reflect your specific interests or address a
problem in your domain of interest. This could involve analyzing public
datasets, building predictive models, creating data visualizations, or
developing interactive dashboards. Choose projects that highlight your
expertise and passion.
v Open-Source
Contributions: Contribute to open-source projects related to data science. This
not only allows you to collaborate with other data scientists but also
showcases your coding skills, understanding of algorithms, and ability to work
with large codebases. GitHub is a popular platform for sharing and
collaborating on open-source projects.
v Data Analysis and
Visualization: Pick datasets from various domains and perform exploratory data
analysis (EDA). Generate meaningful visualizations, uncover patterns,
correlations, and insights, and communicate your findings effectively. Showcase
your ability to extract actionable insights from data.
v Machine Learning
Models: Build and deploy machine learning models for specific tasks such as
classification, regression, clustering, or recommendation systems. Showcasing
your ability to develop accurate models, fine-tune hyperparameters, and
evaluate model performance is essential. Highlight the business value of your
models and their potential impact.
v Data Pipelines and
Automation: Develop data pipelines to automate data ingestion, transformation,
and analysis processes. Showcase your ability to work with large datasets,
handle data cleaning and preprocessing, and build robust and scalable data
processing pipelines.
v Storytelling and
Communication: Develop projects that emphasize your ability to communicate
complex analyses to a non-technical audience. Create interactive dashboards,
write blog posts, or give presentations that effectively convey your findings,
insights, and recommendations in a clear and concise manner.
v Collaboration and
Team Projects: Collaborate with other data scientists, developers, or domain
experts on projects. Showcasing your ability to work in a team environment,
effectively communicate, and contribute to a collective outcome demonstrates
your collaboration skills and adaptability.
Remember to
document your projects well, including details about the problem, the approach
taken, the techniques used, and the outcomes achieved. Showcase your projects
on platforms like GitHub, create a personal website or portfolio, and provide
code samples or documentation to demonstrate your proficiency. Continuously
update your portfolio with new projects, experiment with different domains and
techniques, and highlight your strengths and areas of expertise. A well-curated
portfolio helps you stand out in the competitive field of data science and
increases your chances of landing exciting opportunities.
10) Continuous
Learning: Stay updated with the latest trends and advancements in data
science. Attend workshops, conferences, and meetups. Explore online resources,
blogs, and podcasts dedicated to data science. Engage in online communities and
participate in Kaggle competitions or similar platforms to learn from others
and improve your skills.
Remember, becoming a data scientist is a continuous
learning journey. It requires practice, hands-on experience, and staying
updated with the evolving field of data science.



Comments
Post a Comment
datapedia24@gmail.com